Process Architecture of Postgres
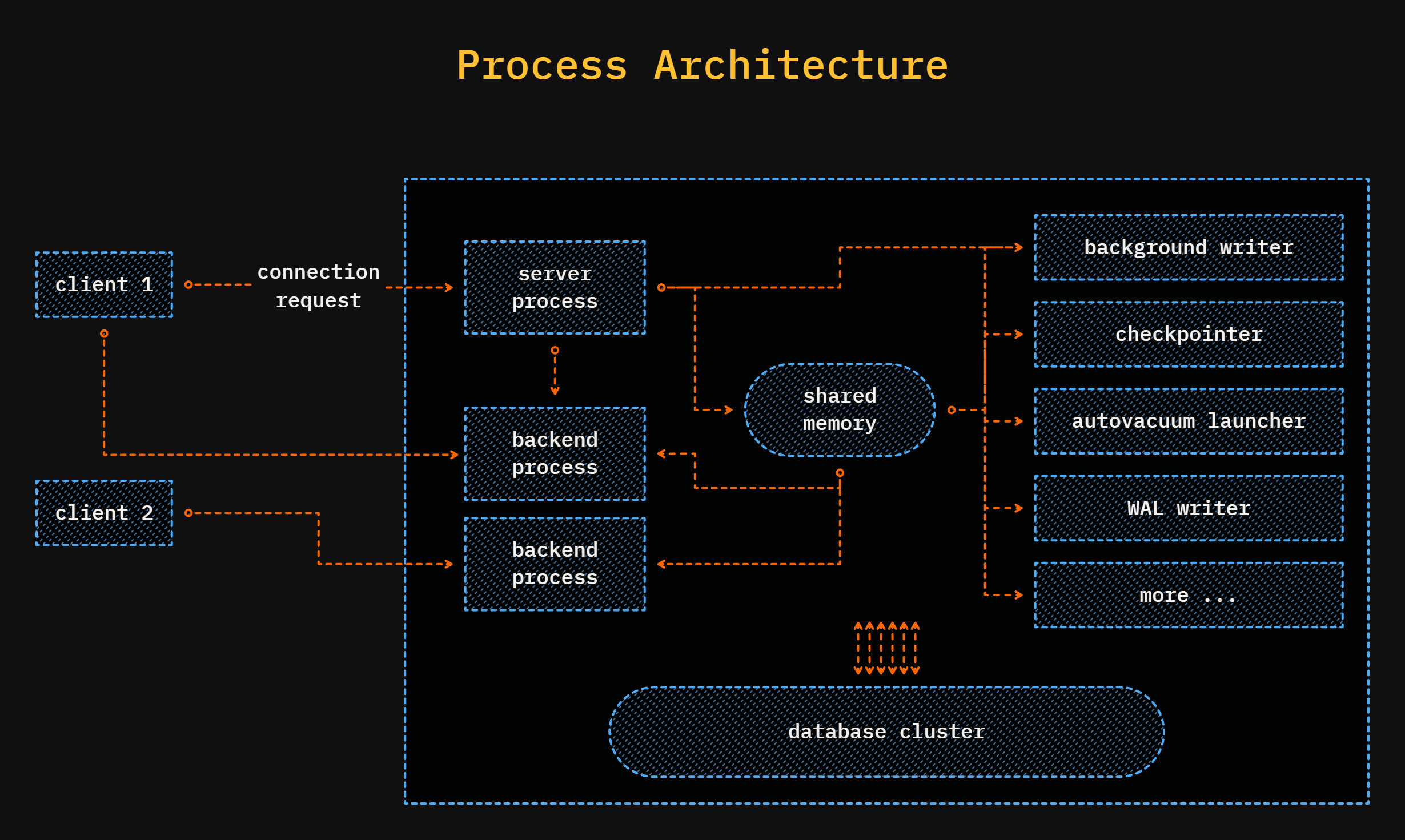
Postgres follows a client-server architecture.
Apps connecting to it are considered clients, and Postgres is itself considered as a server.
Postgres manages everything using processes.
It uses the Postgres Server process or the Postmaster process to handle all admin-level work, i.e. managing other processes.
For handling client queries, it spins up a new process called as Backend Processes.
But the problem is that for each new client connection, it spins up a new backend process, which leads to high CPU and memory consumption.
For that reason, we use pgBouncer or pgPool-II for connection pooling.
Then we have background processes, which handle the rest of the task like replications, streaming, vacuuming, etc.