Query Processing in Postgres
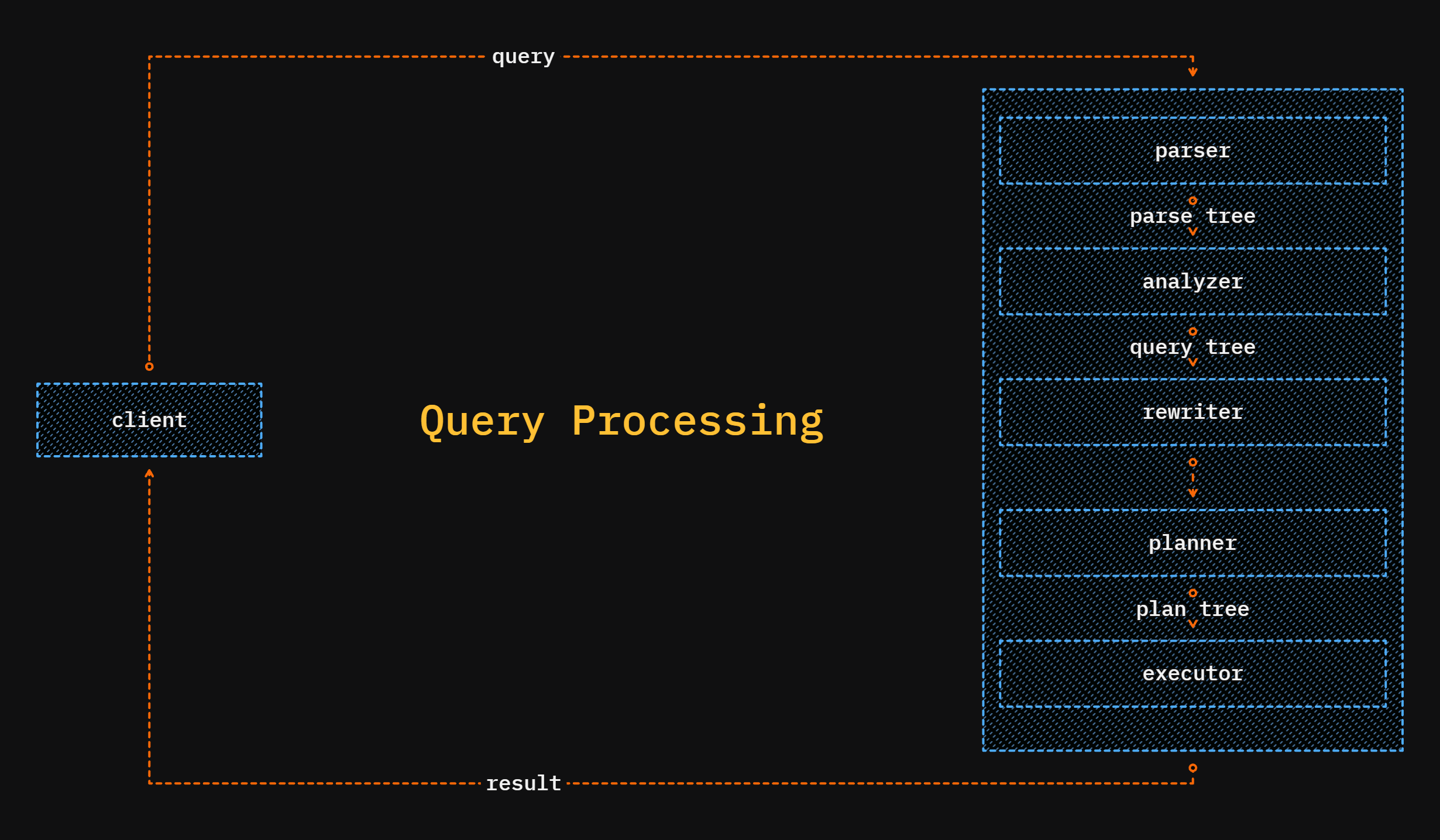
Whenever a backend process receives a query to process, it passes through 5 phases.
Parser:parse the query into a parse treeAnalyzer:do semantic analysis and generate a query treeRewriter:transfer it using rules if you have anyPlanner:generate a cost-effective planExecutor:execute the plan to generate the result
1. Parser
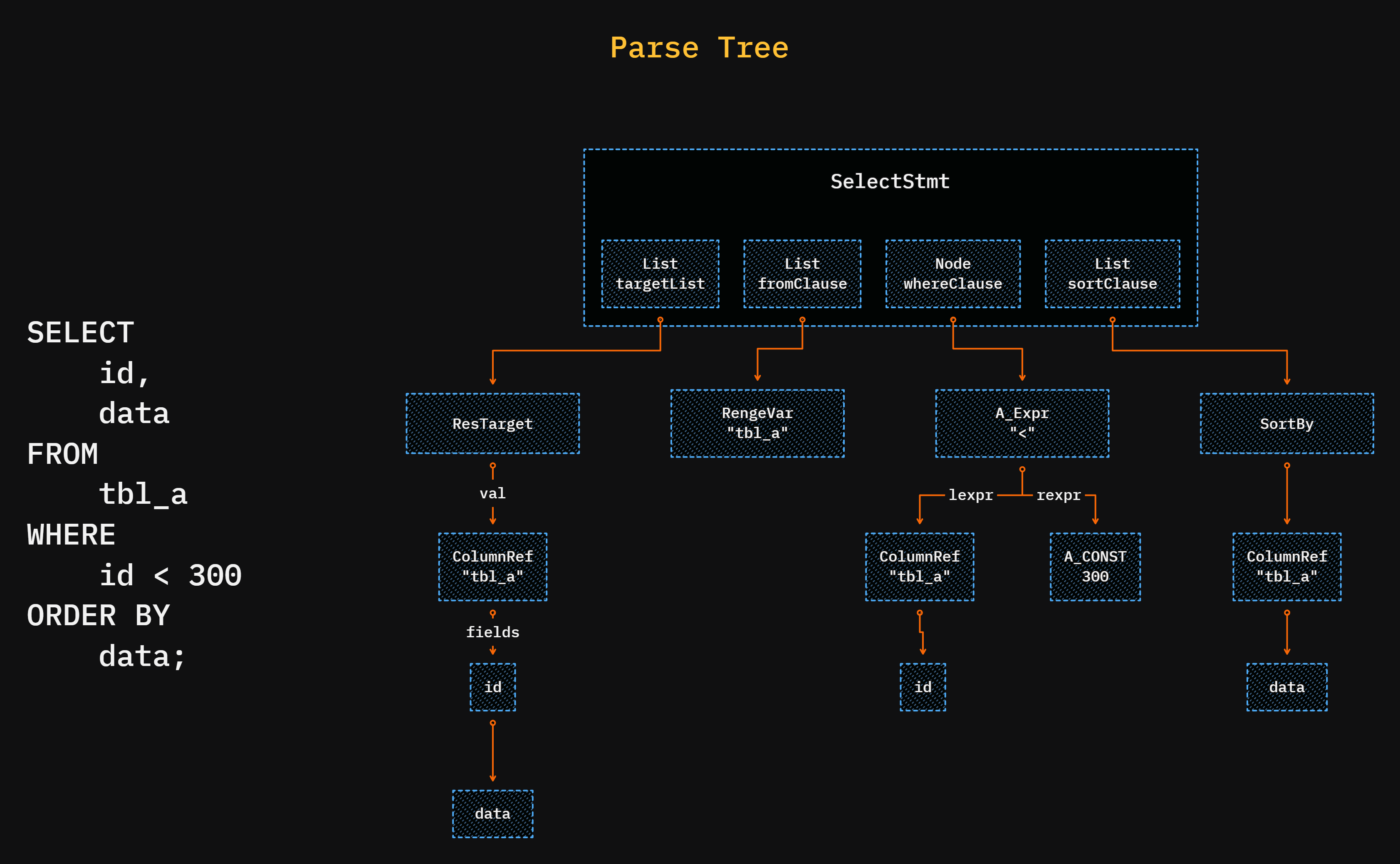
The parser parses the query into a tree-like structure, and the root node will be the SelectStmt.
Its main functionality is to check the syntax, not the semantics of it.
That means, if your syntax is wrong, the error will be thrown from here, but if you make some semantic error, i.e. using a table that doesn't exist, it will not throw an error.
2. Analyzer
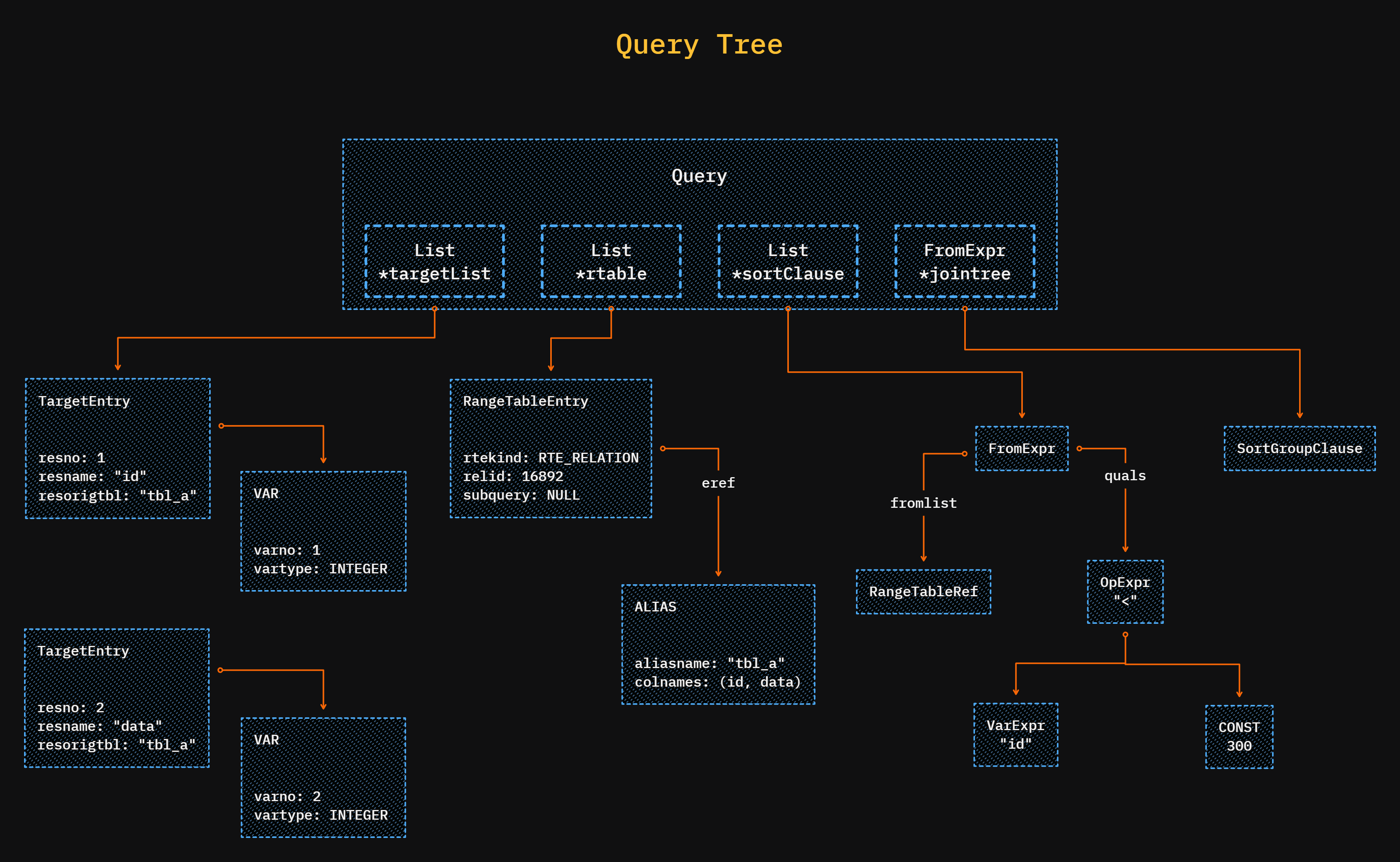
The analyzer takes the parsed tree as input, analyzes it and forms a query tree.
Here, all semantics of your query are being checked, like whether the table name exists or not.
The main components of a query tree are:
targetlist: the list of columns or expressions we want in our result set. If you use the*sign here, it will be replaced by all columns explicitly.rengetable: the list of all relations that are being used in the query. It also holds information like theOIDand the name of the tables.jointree: it holds theFROMandWHEREclause. It also contains information about yourJOINstrategies withONorUSINGconditions.sortclause: the list of sorting clauses While the query tree has more components, these are some primary ones.
3. Rewriter
Rewriter transforms your query tree using the rule system you have defined.
You can check your rules using the pg_rules system view.
For example, it attaches your views as a subquery.
4. Planner
testdb: EXPLAIN SELECT * FROM tbl_a WHERE id < 300 ORDER BY data;
QUERY PLAN
---------------------------------------------------------------
Sort (cost=182.34..183.09 rows=300 width=8)
Sort Key: data
-> Seq Scan on tbl_a (cost=0.00..170.00 rows=300 width=8)
Filter: (id < 300)
(4 rows)
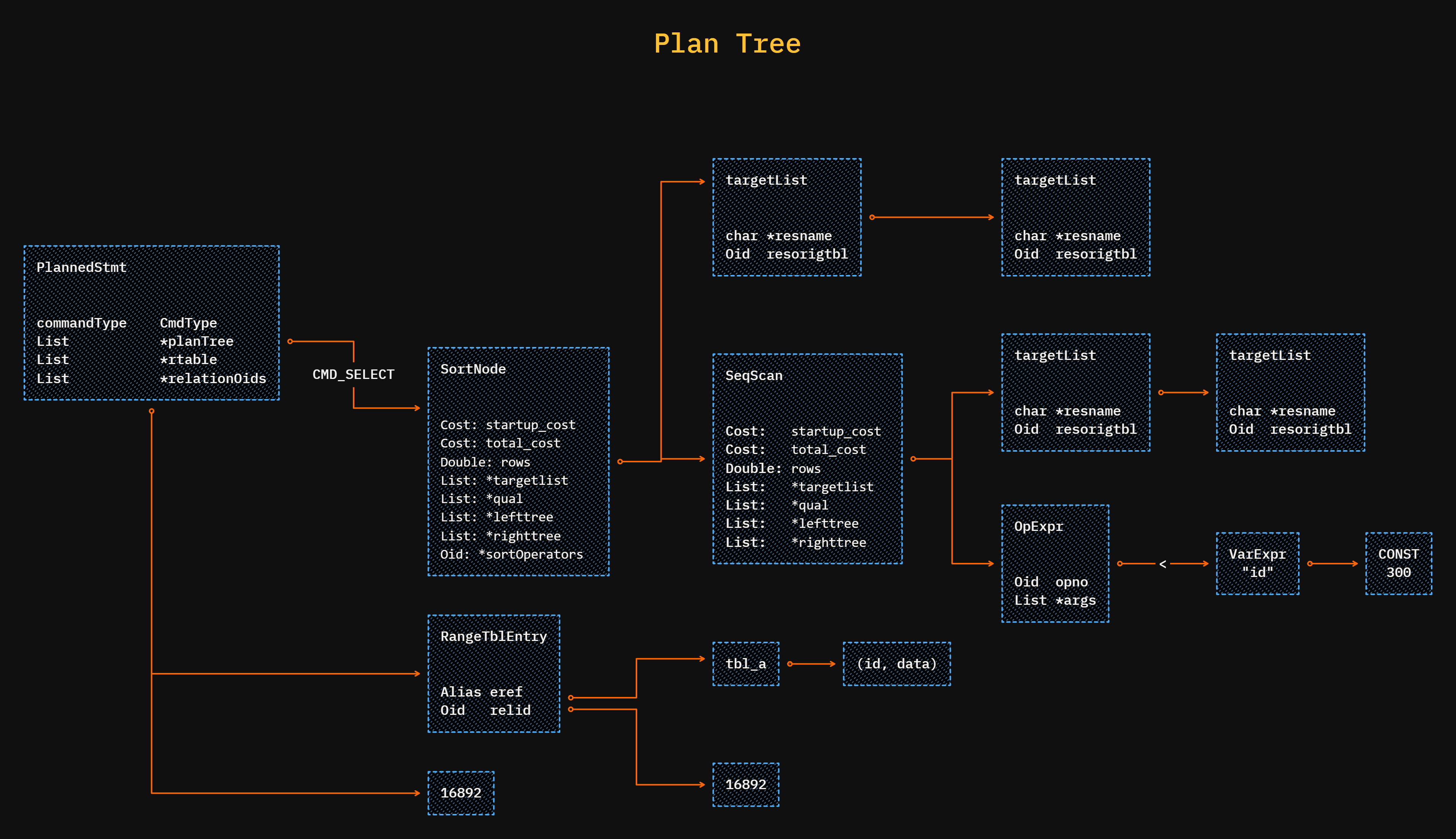
The planner receives a query tree as input and tries to find a cost-efficient query plan to execute it.
The planner in Postgres uses a cost-based optimisation instead of a rule-based optimisation.
You can use the EXPLAIN command to see the query plan.
In the tree form, it has a parent node where the tree starts, called PlannedStmt.
In child nodes, we have interlinked plan nodes, which are executed in a bottom-up approach. That means, it will execute the SqeScan node first, then SortNode.
5. Executor
Using the plan tree, the executor will start executing the query.
It will allocate some memory areas, like temp_buffers and work_mem, in advance to store the temporary tables if needed.
It uses MVCC to maintain consistency and isolation for transactions.